08 Mar 2020
If you want to skip to the goods, click here. If you want to skip straight to the purely professional content, click here.
Foreword
It’s been a while since I spent time writing for personal gratification. My personal and professional journey has lead me pretty far from analyzing exploit kits on a day to day basis. I’ve spent the last three and a half years building out and leading GitHub’s Security Incident Response Team (SIRT) and the processes that guide it. I’ve had an opportunity to take the foundation of how we work laid out by those that came before me, frame it out with scalable and compliant process that fits GitHub’s remote-first, asynchronous-by-default culture, and accelerate it through massive company growth and acquisition by Microsoft. I was something like employee number 310 (not accounting for churn, of course); we’re now over four times that size and still accelerating with an ever growing and awesome platform and product portfolio I’m proud to help protect. I’d be remiss, however, if I didn’t take an opportunity to thank the amazing professionals I’m lucky enough to call peers and teammates, GitHub SIRT would be nothing without their dedication, their creativity, their camaraderie, and their tireless excellence.
With that out of the way, on to the purpose of this post: thinking about risk management and incident response as framed by current events, namely the novel coronavirus officially known as COVID-19. Before we get to the good stuff, a brief disclaimer:
Though this post discusses coronavirus, this is simply a way to frame thinking about the disciplines of risk management and incident response. None of the statements that follow should be interpreted as authoritative guidance on coronavirus or disaster preparedness and all of it is subject to my personal opinion and admitted lack of expertise regarding anything like epidemiology or traditional emergency management. If you’re looking for formal, sanctioned advice, seek out the World Health Organization, US Centers for Disease Control, or your local health authorities. I say again, do not take my personal opinions on and preparations for COVID-19 as professional advice.
Further, my professional background is much more about threat and risk mitigation than forecasting and quantification. There is a formal discipline associated with risk that I have limited formal training in; as such, I tend to simplify risk into a basic framework that allows me to make informed decisions. I have found it effective throughout my life and career, but I have no doubt it could be done more scientifically or more comprehensively.
Coronavirus - A Primer and Personal Approach
Unless you’re living under a rock or in some sort of news-vacuum (ignorant bliss?), you’re well aware by now of the rapid spread of coronavirus, officially known as COVID-19. Believed to have originated in Hubei Province, China, this is a new strain (hence the term novel coronavirus) of a class of cross-species viruses capable of infecting humans. In many humans, the disease appears to be mild, but in some percentage of cases, particularly among the elderly or those with underlying conditions, victims can develop severe and even fatal respiratory complications. Though it’s early and a lot more study is required, COVID-19 appears to spread more readily than the flu and carry a higher (but not outrageous) mortality rate than the seasonal flu.
In terms of perspective and forming the basis of a risk picture, the seasonal flu has sickened between 34 and 49 million individuals this season. The death toll for seasonal flu in 2019-2020 stands somewhere between 20,000 and 52,000 (¹). COVID-19, on the other hand, since its known emergence in late December 2019 and at time of writing on March 8, 2020, has resulted in 109,965 clinically confirmed cases and 3,824 deaths (²). It’s important to understand, that despite these much lower numbers, there’s a substantial amount of uncertainty due to the mild presentation of many cases and the low availability of test kits worldwide. That said, you’re still far more likely to be affected by the seasonal flu than you are COVID-19 unless you happen to reside in a viral hotspot where the disease is more prevalent. That’s about as much explanation as I’m going to give because I’m not really qualified to give it; see the disclaimer above for more authoritative info.
With a basic understanding of COVID-19 established, I want to share some of my personal perspective on the virus and my family’s risk assessment and preparation for it. Below, I’m going to outline some of my thought process, the resulting “threat model” we used, and the preparation we undertook to meet that threat based on our personal situation. All of this has parallels to security risk management and incident response and I’ll discuss that following this section.
Situational Awareness
The first, and perhaps the most important thing I focused on was maintaining well-informed situational awareness, right from the get-go. While I do not consider myself remotely paranoid and I am fortunate enough not to suffer hypochondria in this particular case, I do keep my head on a swivel at a global scale for both personal and professional reasons. Perhaps a decade of security, risk, and intelligence work is the reason for this, but I was sort of loosely tracking this coronavirus outbreak as early as the first two weeks of January.
It wasn’t a focus, I didn’t dwell on it all day, but I did watch closely enough to be able to begin building a mental model for the risk it represented to me, my organization, and to daily life. I paid attention less to the specifics of the outbreak than the shape, size, and velocity of it. This feeds a sort of equation in my head that is constantly re-computing based on the new input I gather daily, for lack of better terms. While there is a formal scientific discipline dedicated to this work, I’m not trained for it, so my internal calculation is intentionally vague and elementary in nature. The point is simply to be able to track the overall trend represented by developments related to coronavirus and how the basic risk I assign any event or circumstance, in this case COVID-19, is growing or changing. Understanding this, even within my own mental framework, is the basis of how I make informed decisions with risk in mind.
It is absolutely vital that you maintain situational awareness at all times. Failure to identify and assess a risk in the first place leaves you unable to prepare, rendering your ability to level the playing field as much as circumstances permit essentially null.
Building a Basic Mental Model of The Problem
My next step is to begin developing mental models around the problem and its possible manifestations. In the case of COVID-19, I began thinking about some plausible long-term outcomes. Those outcomes roughly looked as follows and are oversimplified, discounting a whole lot of good epidemiological science about things like R0 and mortality rates among other things:
- Virus is largely contained by aggressive response in China and fizzles as the warm season approaches, remaining only an isolated and periodic threat relegated to dozens or fewer easily isolated cases per year.
- Virus is not contained, but does not readily spread. Slowed by control and isolation efforts, it does spread globally or regionally, but is limited to local clusters and eventually snuffed out before the following flu season.
- Virus is not contained and spreads rapidly in an increasingly interconnected world. Governments in free societies or underdeveloped nations struggle to contain local clusters and rapid community transmission occurs. Seasonal impact is high, akin to other modern seasonal flu epidemics (see 2009 or 1957-1958) but eventually slows to a crawl and peters out, representing no threat greater than a moderate flu pandemic.
- Virus is not contained, spreads rapidly and with limited impact from control and isolation efforts. Virus develops a rather severe mortality rate and has a major global impact, presenting a substantial risk to health and way of life for one or more years. An example might be the flu pandemic of 1918.
Keep in mind that these models aren’t set in concrete and they change as time goes on and things change on the ground; I’m constantly re-calculating them. These models shouldn’t be static and should adjust to the reality you face. On a personal level, I suspect we’re looking at either the third or fourth model at this point. Much remains to be seen, but those models are the basis upon which I am operating today.
Develop a More Nuanced “Threat Model”
Now that I understood the basic shape of the problem, I wanted to think more concretely about what the actual threat looks like. My wife and I discussed (and continue to discuss) our mental threat model and this is the set of things we selected as threats, based on our home and life situation:
- Possibility of voluntary or mandatory at-home-isolation for as long as a month due to local outbreak
- Possibility of temporary (lasting a month or two at maximum) supply shortages of items like food, medicine, paper products, and cleaning supplies
- Increased risk related to public gatherings or travel via public transit
- Possibility of caring for one or more sick and contagious persons at home with limited external assistance
Things we decided to exclude from our model based on available evidence:
- Water shortages or water quality problems (some preppers out there are probably incensed at this decision)
- Utility outages
- Large-scale societal breakdown or zombie apocalypse
Identify your Assets and Vulnerabilities
The next step for us was asset identification. We wanted to think deliberately about what we needed to protect and any special considerations that affected those things. We identified the following critical assets, all living things due to the nature of the problem:
- Two adults
- Two school-age children, the most important assets we have to protect (talking about your children as assets is admittedly uncomfortable)
- One indoor cat
With the basic assets identified, we set out to think about the things needed to keep them happy and healthy, with an eye toward identifying vulnerabilities or gaps that might increase our risk if unaddressed:
- One of the adults in our home has substantial underlying conditions that may place them at increased risk for infection and subsequent complications
- One adult has a significant dietary restriction which requires low fat consumption
- Both children are in public school, which represents a substantial vector for transmission
- We don’t keep deep stockpiles of most things, we’re prepared for brief life interruptions, but nothing beyond a week or ten days
Prioritize and Prepare
Incident response, whether it be related to an epidemic or otherwise, is all about effectively mitigating as much of the risk represented by that incident as possible. In order to do this effectively, you need to be prepared before the incident begins. Regarding COVID-19, this meant that once we developed situational awareness and took stock of our threats, assets, and vulnerabilities, we needed to begin preemptively addressing those things. We began by collecting information related to epidemic and disaster preparedness from sources such as the CDC, FEMA, WHO, and others. We developed a simplistic spreadsheet of items we needed to stockpile as well as a to-do list.
Once we had a basic list, we began prioritizing that list based on our own ground-truth surfaced via the threat, asset, and vulnerability analysis we already completed. For instance, we know we have an adult with underlying conditions, we therefore assume the likelihood we will need to self-isolate is higher than the population at large and that we’ll need to do so sooner. Therefore, we accelerated our purchasing of absolutely essential items like food and critical prescriptions a number of weeks ago.
We also know that with two public-school age children, we’d need to be more aggressive than the average household in disinfecting and personal hygiene, particularly in light of the health conditions of one of the adults. Therefore, we prioritized cleaning supplies, hand soap, and hand sanitizer early on and bought them in responsible quantities before any sort of public panic set in.
Many of you are probably wondering about masks, particularly N95 masks. We deprioritized them aggressively because they’re difficult to fit, wear, and dispose of properly, making the effectiveness substantially lower for non-medical professionals. Further, masks really need to be preserved for medical and emergency response personnel as much as possible. All that said, because of the vulnerable adult in our home, we did purchase a small quantity, primarily to be worn by someone who is already ill inside the home. The intent is not to wear these in public day to day in a futile effort to reduce daily exposure, but instead to lower the risk of in-home transmission if, and only if, someone becomes ill while we’re isolated.
We also took care to prioritize some things people don’t generally think of until it’s too late because we took the time to look at our threats, assets, and vulnerabilities. Extra cat food and cat litter are perfect examples, as were our food purchasing choices; whereas many tend to stockpile comforting foods high in fat, we needed to make different choices based on our health situation. Instead, we’re stockpiled with lower-fat choices like beans and lean meats like chicken breast. Further, with a couple of young children, we made some deliberate choices designed to keep spirits up in tough times. We prioritized some fun snacks and silly foods that will add variety and spark joy during a monotonous isolation should one come to pass.
A final note on stockpiling and disaster preparedness: these things live on a spectrum and some folks have a very different personal risk calculation. We took a fairly lightweight approach to our preparedness. If full societal breakdown was part of our threat model, we’d be having a very different conversation that would drastically affect our day to day lives just to prepare. In our case, we basically deepened our stockpiles of things we already use every day. None of what we purchased will go to waste or burn a hole in our pocket if COVID-19 fizzles out.
While I’m hopeful COVID-19 fizzles out as the warm months approach, I now feel much more confident when faced with the possibility it will instead disrupt our lives in a significant way.
Thinking about Risk
Preparation for COVID-19 is nice, but why does any of that matter if you’re here to read about security? The answer is simple: the basic framework I applied to assess and prepare for the risk represented by COVID-19 is the same one I apply at work every day and there are lessons to be learned and reinforced from that experience that can be useful in our day-to-day professional lives.
The process I use boils down to the following:
- Keep your head on a swivel, never stop consuming data about potential problems. Identify and track potential problems early and often. Calculate and constantly re-calculate a basic trend for any potential problem - understand if it’s becoming more prevalent or impactful so you can begin preparations before it’s too late.
- When a given problem becomes relevant enough to begin preparing for, build a simplistic model of the problem and its potential outcomes, even if only in your head.
- Identify the threats posed by that problem, the assets you need to protect, and the vulnerabilities or gaps you have surrounding those assets.
- Prioritize and prepare based on a combination of the possible outcomes, the threat model you built, and the ground-truth regarding your assets and vulnerabilities.
- Though I didn’t cover this above, documentation is the final step in my process. Where time allows, you should not allow all the hard work in steps one through four go to waste. If the risk fizzles out, you have fantastic prior art to reference should it reappear later.
Some additional points to keep in mind when thinking about risk:
Paranoia is unhealthy, we have lives to live and businesses to run.
Awareness of and preparation for risk does not mean that you stop the presses, hole up in your home, or stop your organization from doing business in order to avoid a risk. As security professionals, we’re in the business of mitigating or preventing risk as much as possible, not eliminating it. Do not let preparation affect your organization’s goals and success; instead, protect and enhance the success of your organization by insulating it from risk with careful preparation that does not inhibit progress.
Your preparation should never harm others - or your business.
An extension of the point above, risk preparedness should never be completed at the expense of others. In our personal lives this means responsible supply purchases well before panic buying sets in. It means not panic-buying all the hand sanitizer or masks, which you’ll never use, at the expense of other families or medical professionals. In our professions, this means that we don’t require absurd and expensive risk reduction measures in the name of security alone. We instead take a balanced approach to risk preparedness and reduction with our productivity and efficiency in mind.
Track problems early and often, even if you can’t or shouldn’t act on them now.
If you make a regular habit of identifying and trending various problems, you will be infinitely better situated to prepare for and respond to them if circumstances require. In our COVID-19 case, this meant that I was preparing in February and way ahead of the game here in the United States; I wasn’t subject to supply shortages or the panic buying now taking place. At work, this means that we’re planning and prioritizing day to day work with possible problems in mind on an ongoing basis. Where possible, we rely on an inventory of possible risks to better inform resourcing and technical decisions every day instead of blindly checking checkboxes from some compliance checklist.
In short, risk awareness and preparation are really the name of the game. Bad things happen - that’s why incident response professionals exist after all. If you’re already aware of those bad things, know how they might manifest, and have completed reasonable preparations, you’re going to be able to respond and mitigate the risk much more effectively.
Incident Response and Communication for Incident Coordinators
You’ve been minding the shop and you’ve successfully identified and prepared for a given risk, but now it’s on your doorstep and you’re forced to respond - what happens now? I won’t be discussing incident response in depth here, but I do want to highlight some critical items that are particularly important for incident coordinators specifically - and relevant to current events.
If you actually have prepared, the first step is the easiest: have an effective incident response process in place. This should be well documented, it should define all the inputs and outputs of the process in accordance with your organization’s needs or compliance and regulatory obligations, and it should clearly delineate all the major IR stakeholders and their responsibilities. Most importantly, it should be easy to digest, easy to operate, and readily repeatable for any kind of crisis. Have this figured out before you’re facing that crisis. If you don’t, you’ll lose valuable time during the event and lost time usually results in more risk.
During an incident, as incident coordinator, it is your responsibility - your duty - to set the tone and lead from the front. Responders, whether security professionals or otherwise, rely on the incident coordinator for their example. If you panic, the rest of the team will likely do so as well; if - instead - you respond with calm and confidence, chances are you’ll make everyone in the room a more effective responder.
This doesn’t mean you make decisions in a vacuum or act like a tyrant. You’re neither omniscient nor omnipotent. If you make decisions without care and consideration and fail to collaborate with the talented professionals that make up your response team, you’re adding substantially to the risk incurred and it’s possible you’ll accidentally pour gasoline on the figurative dumpster fire. You should seek to make decisions by consensus and make those decisions guided by data as often as possible. That said, sometimes you may have to break a tie in deliberations or rely on your experience or even your gut to make a tricky decision. This is where it’s critical to set the course confidently, document your decision making reasoning, and orient the team to that course.
In terms of coming to those decisions, it is critical that action must be swift and decisive. Inaction is the enemy, whether by lack of preparation or analysis paralysis. Inaction delays mitigation, demoralizes responders, increases the risk incurred by the incident, and makes loss of victim or public goodwill more likely in the event that the incident goes public. As incident coordinator, keep the response tempo up and ensure the bias is toward action. Do not act rashly at the cost of analysis or consensus, but ensure that efforts to develop those things are always moving forward with clear deliverables and timelines established and understood by all responders. If things get stuck, it is important to call this out and either immediately clear the roadblocks or carefully make a decision to move ahead with the best information available - this is where past experience or your gut sometimes play a part. That leap of faith can be a nerve-wracking and imposter-syndrome inducing situation, but be confident in your skills and experience and let them light the way forward for you.
Once a direction has been established, no matter what part of the incident response process you’re in, that direction must be communicated unequivocally and with perfect clarity. No one in the room should be unaware of or uncertain as to the current course of action and their own responsibilities. If they are, for some reason, that course of action and those responsibilities should be quickly, easily, and clearly discoverable. Keeping status summaries and responsibility assignments up to date in a well-known and accessible location is critical and should be a top priority for the incident coordinator. Nothing will feed chaos and increase risk more than a room full of people without clear direction and assignments running in different directions and working at cross purposes.
Finally, extend these principles, particularly regarding clear, decisive communication when informing customers or the public. If clear and decisive communication are critical inside a room full of professionals, imagine how important they are for an uninformed or unprepared public or customer audience. All of your communications with external parties should make it very clear, in plain english, what happened, how it affects them, what you’re doing to respond, what they can do to help themselves, and where they can get help. Delivering anything less only compounds the incident by causing confusion, inciting concern or panic, and adding work for responders that get tied up in responding to a million questions and clarifications.
Incident response is a broad discipline and circumstances can vary wildly from event to event, but I’ve generally found that the principles above can and should be applied at all times. These aren’t specific technical to-do list items; they’re a philosophical approach for clear incident response coordination, leadership, and risk mitigation. These things make any incident coordinator, in any situation, a more effective force multiplier for a capable and prepared incident response team, which is the crux of the role.
A Call to Action - For Incident Responders, Public Health Professionals, and Emergency Management Leaders Alike
Too often, I see, hear, or read about incident responders wrapped up in the technical nuts and bolts of their professions. In the case of COVID-19, I see a lot of discussion about the technical intricacies of R0(the reproductive factor of the virus, or how easily it spreads from one host to others) or the mortality rate in clinical environments. In the security profession, it’s endless presentations and blog posts about the specifics of a hot new exploit or analysis technique. To be clear, these things matter immensely and have their place in our professions, but it’s vital not to focus on these things at the expense of some of the fundamentals, particularly in the role of incident coordinator.
To those working in incident response, or emergency management, I’d encourage you to buckle down on your risk management practices, your leadership and decisiveness, and your communication. These last few weeks, various governments and health agencies across the globe have been criticized for poor preparation, slow decision making and dissemination of those decisions, poor decisions made with incomplete data, and public messaging as clear as mud.
These things matter. Response time and effectiveness is risk. If we’re slow and perform poorly, risk increases. If we’re decisive and effective, it declines. In responding to epidemics, this is especially so (³):
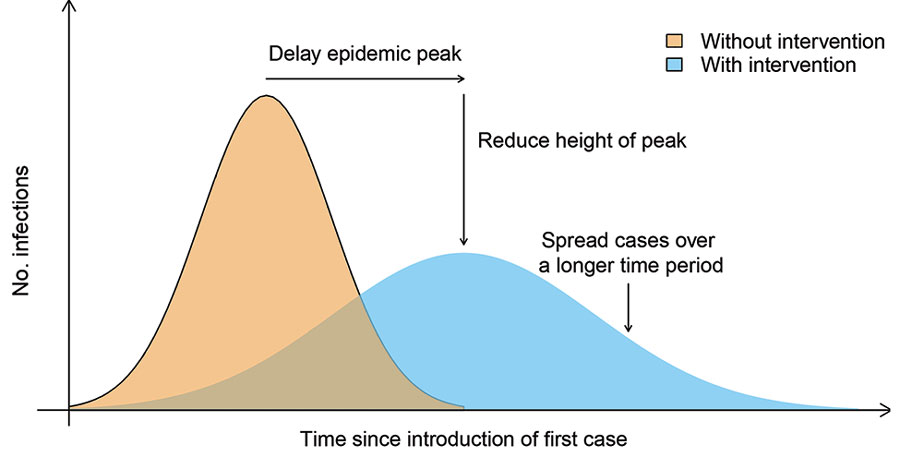
While we can’t prevent the likes of COVID-19 or the security incidents we’re responsible for entirely, we can be better prepared and respond more effectively. If you do nothing else, prepare yourself, your organization, or the public on a constant basis, take decisive data-driven action swiftly, and communicate that action with indisputable clarity.
As always, I welcome your feedback; please reach out @swannysec.
¹ https://systems.jhu.edu/research/public-health/ncov/
² https://www.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6
³ https://wwwnc.cdc.gov/eid/article/26/5/19-0995-f1
For more on Coronavirus risk from a business perspective:
07 Mar 2017
The Rise and Fall of an Empire
Angler, and to a lesser extent, Nuclear, were the predominant exploit kits (EKs) of 2015 and the first half of 2016 before suddenly disappearing early last summer. With plenty of money to be made on the distribution of ransomware and banking trojans, other EKs quickly filled the void. Neutrino and RIG were the first to respond, though Neutrino itself disappeared in September of 2016.
Around the same time, Empire, a privately-sold EK with roots in the more widely-available RIG kit, appeared on the scene, ostensibly to steal a piece of the crimeware pie. Sometimes referred to as RIG-E, Empire delivered a wide variety of payloads during the fall of 2016, including custom ransomware and banking trojans. According to Brad Duncan over at Malware-Traffic-Analysis and Palo Alto Unit42, Empire was often utilized by the EITest campaign, which had previously utilized Angler in great quantities.
Unfortunately for the purveyors of Empire, and fortunately for the rest of us, Empire’s reign was short-lived. Like its predecessors Angler, Nuclear, and Neutrino, Empire itself mysteriously disappeared at the end of December 2016.
Nebula Appears
While Empire enjoyed only a short period in the sun, RIG itself continues to operate successfully as does Sundown, another exploit kit seeing success in the wake of Angler. Additionally, it seems a new contender has appeared, seeking to take up the slack left by Empire. Seemingly a hybrid of Sundown and Empire, Nebula, first appearing for sale on February 17th, integrated an internal traffic direction system (TDS) seemingly salvaged from the ashes of Empire. For more information, check out Kafeine’s excellent post here.
As a long-overdue exercise in crimeware analysis using OSINT, I decided to take a crack at examining the Nebula EK infrastructure in an attempt to better understand the actors utilizing it and the payloads being delivered. What I found was both amusing and unexpected for an exploit kit so new to the scene.
All of the tools I use to perform this analysis are available either completely free of charge or as full-featured community editions. For visual analysis, I use Paterva Maltego. As data sources used to expand on and add context to the blogs of Kafeine and Brad Duncan mentioned above, I use ThreatCrowd, ThreatMiner, Alienvault OTX, and RiskIQ’s PassiveTotal. All of these offer transforms for Maltego either directly or via other community members.
Brian Krebs: EK Peddler
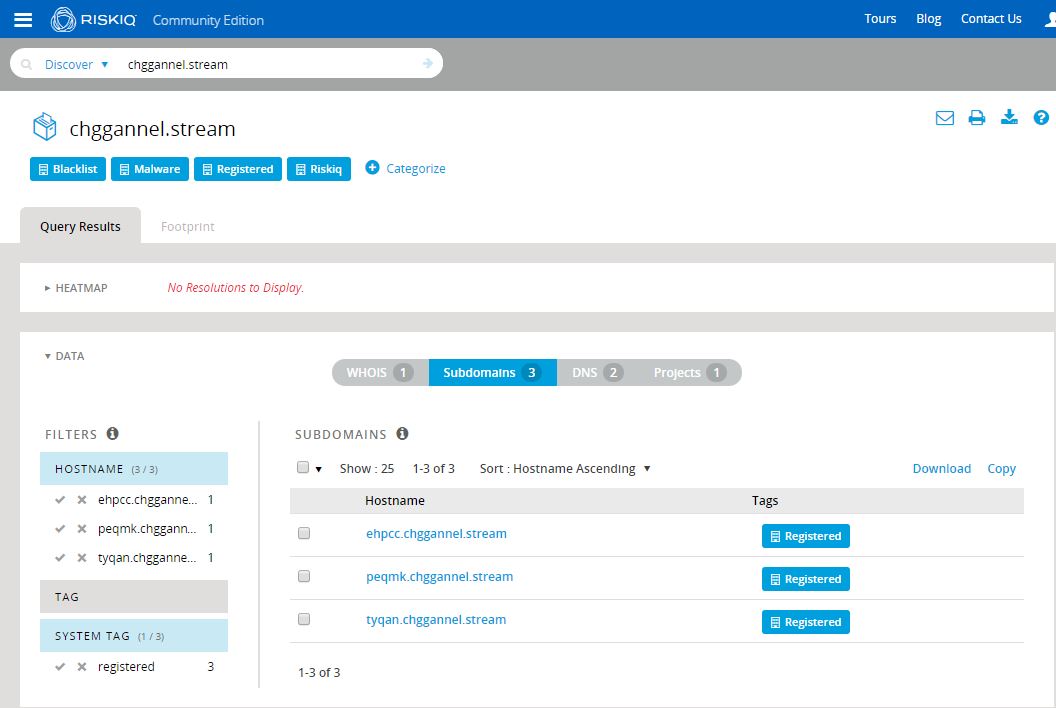
Analysis begins with a single Nebula EK delivery subdomain provided by Brad Duncan’s analysis of a recent Nebula infection chain: ehpcc.chggannel[.]stream. As a starting point, I dropped the subdomain into PassiveTotal:
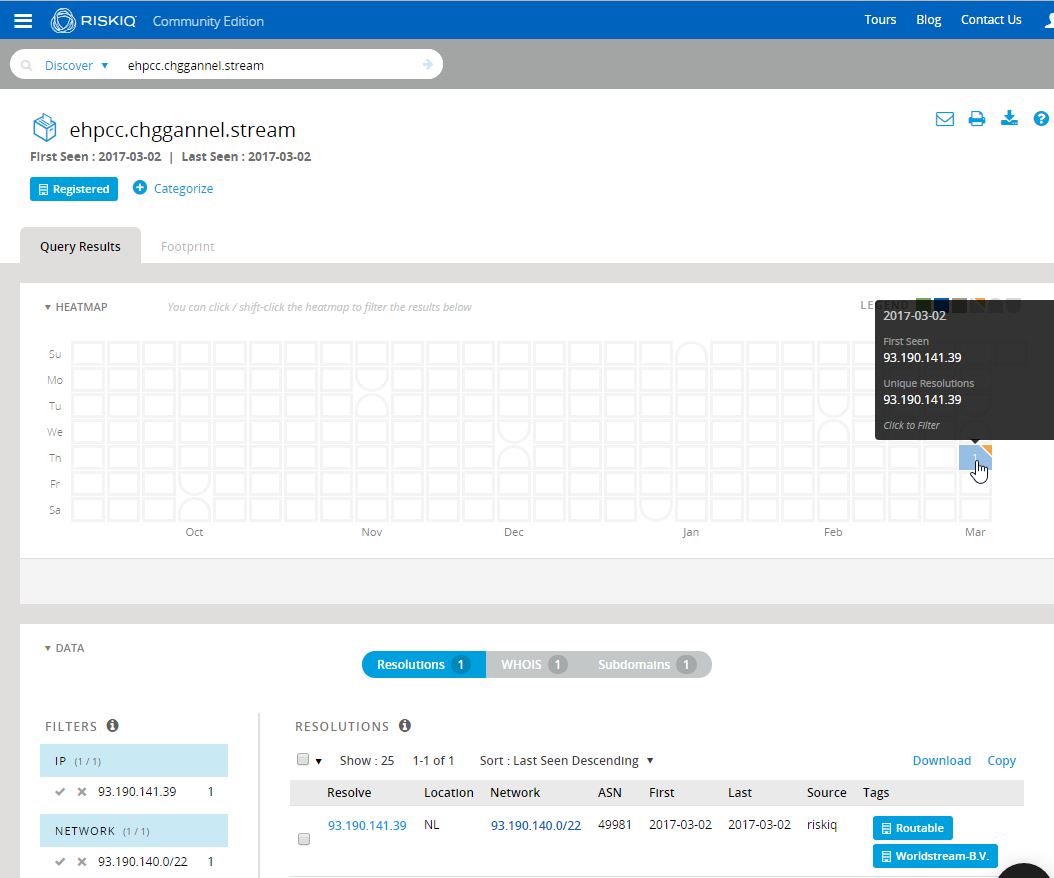
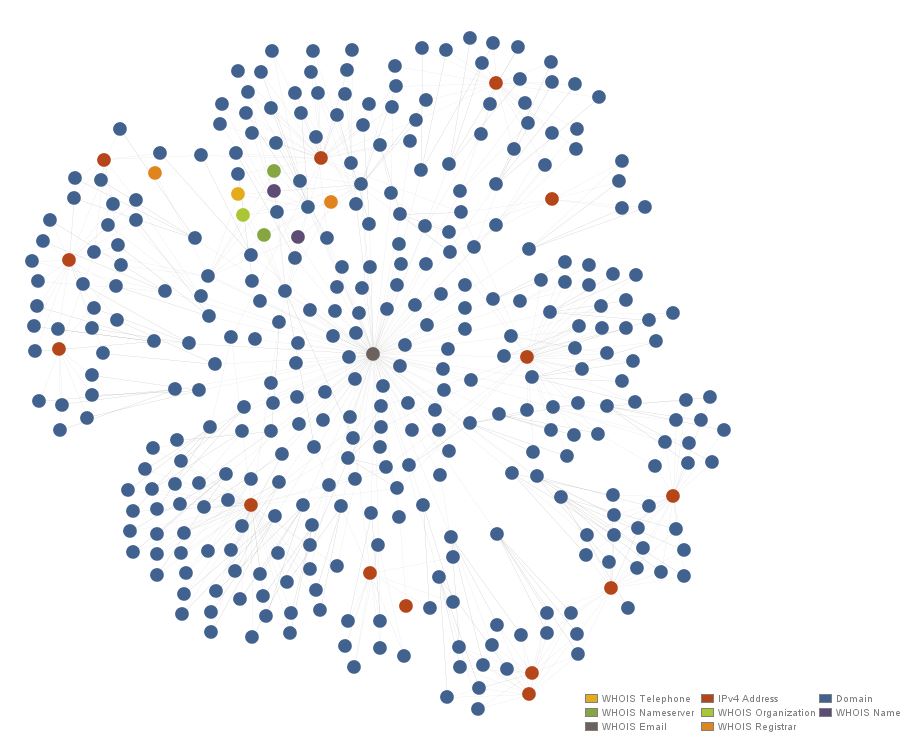
Clearly, the subdomain is brand new, having been first seen (and in fact, last seen) on March 2nd, resolving to a Worldstream IP out of the Netherlands. We’ll come back to the IP and the rest of the chggannel domain in a moment. What immediately proved far more interesting to me was the whois record for the domain. Whois pivoting is not always reliable, nor is it always even possible, depending on the registrar used and the OPSEC practices of the actor. Fortunately, in this case, the actors gave us something to work with.
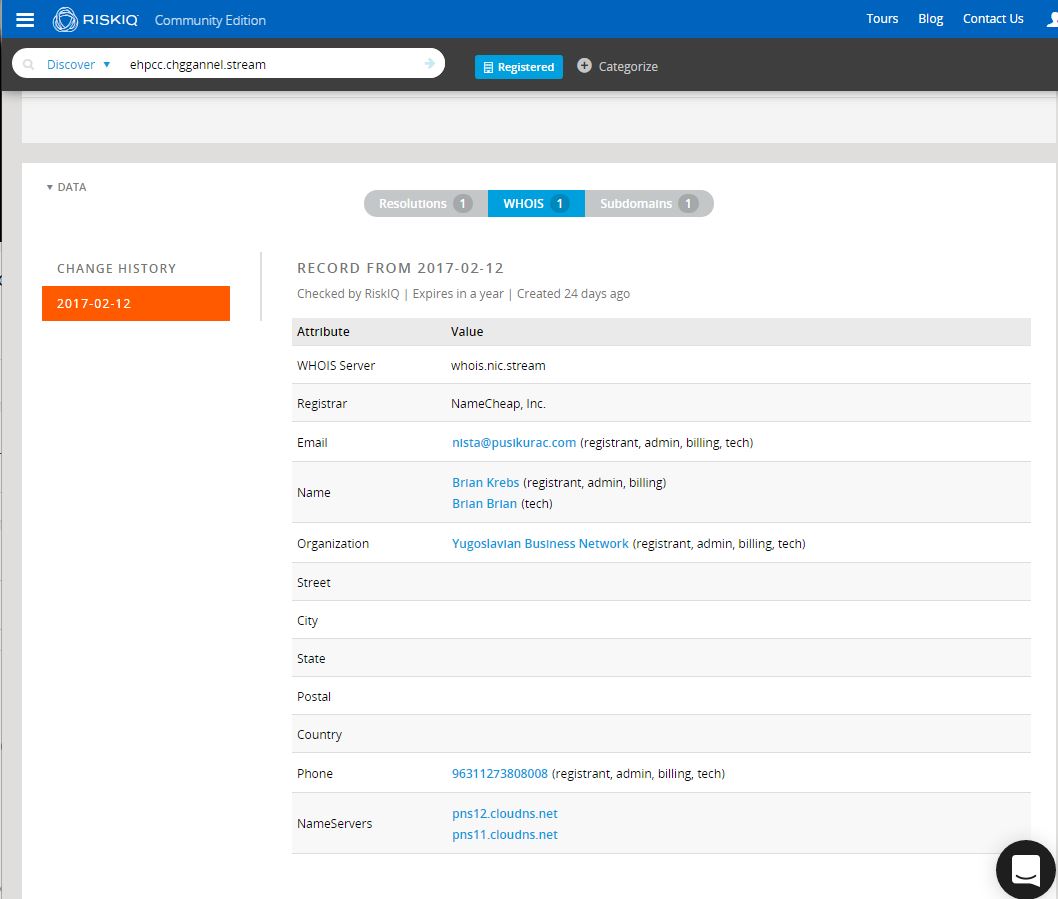
So it seems Brian Krebs has turned to a life of crime and is now a member of the Yugoslavian Business Network? As amusing and unlikely as that is, we likely have a couple of interesting indicators to work from, including a whois name, e-mail, org, and perhaps a phone number. PassiveTotal is a fantastic source for this kind of data and we should be able to pivot on those indicators to learn more, provided the actors have used them with any consistency. Before we move to Maltego and continue exploring, let’s check out the rest of that domain. Looks like there are two other subdomains here, giving us a good starting point to work from:
We’ll go ahead and drop the domain into Maltego and add in the other Nebula domains provided by Brad Duncan’s post. As a first step, we’ll pull in the whois details for all four domains to see whether or not we have consistent indicators to work with:
Sure enough, we’ve definitely got consistent use of the same data for the whois records.
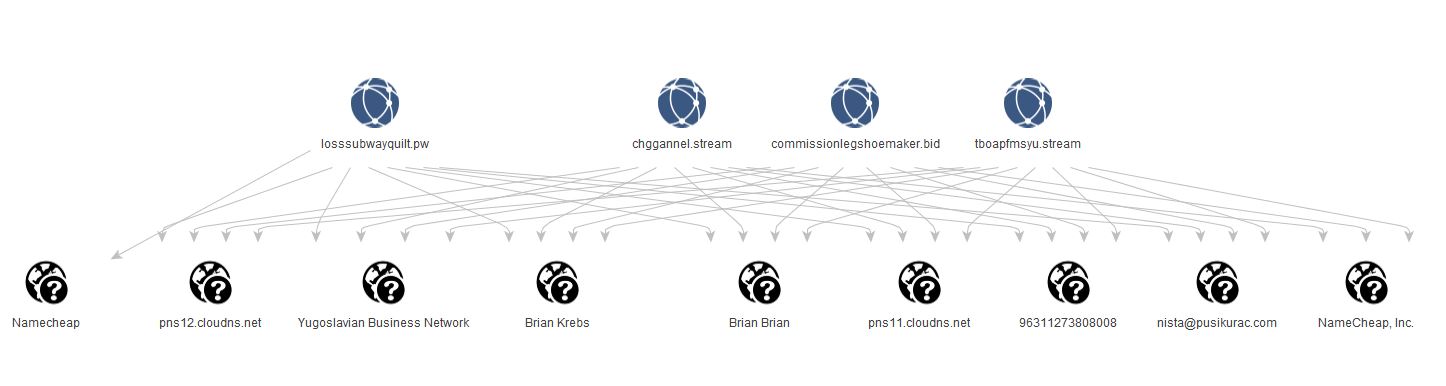
Quickly pivoting through the registrant name, e-mail, org name, and phone number in PassiveTotal show that the e-mail and phone number have the most consistency, as there are obviously some legitimate domains registered by real people named Brian Krebs. There are an identical 114 domains registered with the nista@pusikurac[.]com e-mail adress and the same phone number. We’ll go ahead and pivot inside Maltego off the e-mail and pull back all the domains PassiveTotal knows about registered with that address.


Pivoting from these new domains to their IPs by pulling the Passive DNS results from PassiveTotal brings back a whopping one IP. Why? Mr. Krebs seems to be making extensive use of subdomains. The second screenshot shows what happens when we pull in all the subdomains for the domains present, the entity count of the graph nearly triples.

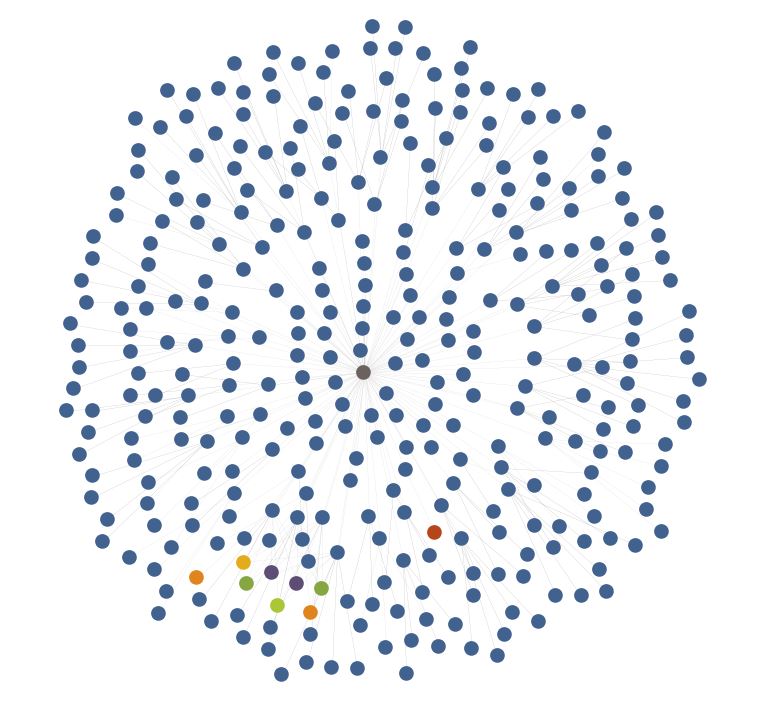
Once more pulling in the IPs via Passive DNS, we see that 300+ domains and subdomains return to only fourteen IPs, in the red-orange color. It should be noted that a few of these IPs are shared webhosts and that the legitimate domains are not displayed on this graph.
Unfortunately, ThreatCrowd, ThreatMiner, and Alientvault OTX all return no results when I attempt to query for malware samples observed at the domains registered by this actor. Further, none of the domains or subdomains host SSL certificates according to PassiveTotal. Accordingly, we’ll wrap up our pivoting here, having exhausted the unique whois indicators provided by the Nebula actors.
Nebula’s Extent and Payloads
In order to clean up the graph and ensure all the data is likely relevant to Nebula, we want to take a look at the registrations from a temporal perspective. Of the 114 domains registered using the farcical Brian Krebs moniker and nista@pusikurac[.]com at the time of writing, 12 were registered in May of 2016. All 12 of these domains were also registered under a different whois org name, ISP. Since February 8th, 2017, 102 domains have been registered under the Krebs/nista@pusikurac[.]com combination, of which 97 used Yugoslavian Business Network as their org name. Curiously, however, the 12 domains registered earlier have active subdomains observed during the recent Nebula campaign.
Little additional information can be gleaned from the OSINT sources I have available to me, but from the analyses performed by Kafeine and Brad Duncan, we know that Nebula leads to a variety of payloads including DiamondFox, Gootkit, Ramnit, and Pitou. With the exception of Pitou, which is a spambot, all of these are bankers. At this time, there is no evidence the Yugoslavian Business Network actors are distributing ransomware via Nebula.
Conclusions
The Yugoslavian Business Network actually has a significant history with the Sundown EK. According to Ed Miles at Zscaler, the first indications of Yugoslavian Business Network involvement with Sundown began in July of 2016. At this time, however, it was unclear how the group, which advertised their coding services in German on forums, was associated with Sundown. By September, Trustwave indicated that the Sundown actors had “outsourced” their DGA work to the Yugoslavian Business Network. By the end of October 2016, Nick Biasini at Cisco’s Talos Intelligence concluded that Yugoslavian Business Network indicators were associated with all Sundown landing pages and that Sundown’s actors were operating a very large domain shadowing and wildcarding operation to power the exploit kit’s spread. Interestingly, he also concluded that the payloads from this operation were exclusively banking trojans.
Given the close historical ties between Sundown and the Yugoslavian Business Network, it is probable that Nebula is simply a new iteration on the existing Sundown exploit kit, operated by the same actors or a closely related group of actors. The willingness of the Yugoslavian Business Network to flaunt their moniker throughout their involvement with Sundown squares with the appearance of that name in the whois records for the Nebula campaign. Additionally, two other calling cards of the YBN appear to be present in the Nebula campaign, the use of subdomains/domain wildcarding and the almost exclusive delivery of banking malware vs. ransomware. Finally, the gang at Digital Shadows has additional details, including tweets from @CryptoInsane and @666_KingCobra (the alleged author of the Terror exploit kit) which seem to indicate that the Nebula source code offered for sale is in fact that of Sundown.
As an alternative hypothesis, it is possible that the Nebula activity I have analyzed here is indicative of a copycat operation, designed to look like the Sundown/YBN activity using the leaked source code. However, I believe that the balance of the evidence supports the original conclusion and that this is probably not a copycat operation.
In a follow-up to this post, I will be detailing the process of using PassiveTotal to set up a public project and the monitor function to track the YBN actor and Nebula campaign. IOCs are provided below. As always, I invite comment, debate, or criticism @swannysec.
IOCs
Passive Total Project
https://passivetotal.org/projects/80ab2f3f-e08f-f86a-fade-6f9d3f8a12c6
Alienvault OSX Pulse (Note: Due to an ingestion issue, not all domains/subdomains present)
Domains/subdomains
half-sistergoalindustry[.]pro
deficitshoulder.lossicedeficit[.]pw
hulbyking[.]stream
supportpartner.lossicedeficit[.]pw
tafgste[.]stream
siberianbangladeshtransport[.]win
commissionmice.lossicedeficit[.]pw
brabynch[.]stream
ovalsharevault[.]info
tom-tomchardcomparison[.]club
birthlasagnaexplanation[.]info
rootym[.]stream
knowledgedrugsaturday[.]club
qgg.losssubwayquilt[.]pw
hmn.losssubwayquilt[.]pw
chggannel[.]stream
tboapfmsyu[.]stream
offertom-tom.commissionlegshoemaker[.]bid
bitpurchasetempo[.]loan
signaturelilac.commissionlegshoemaker[.]bid
decimalyugolead[.]pro
commissionlegshoemaker[.]bid
mistmessage.commissionlegshoemaker[.]bid
losssubwayquilt[.]pw
profitwhiskey.commissionlegshoemaker[.]bid
suggestiondentistrectangle[.]club
bandfactorycroissant[.]bid
begoniamistakemeal[.]club
facilitiesturkishdipstick[.]info
textfatherfont[.]info
canfragranceretailer[.]site
certificationphilosophy.decimalyugolead[.]pro
harborinterestrecorder[.]club
pheasantmillisecondenvironment[.]stream
jebemtimater[.]xyz
retailergreasebottom[.]win
transportdrill.facilitiesturkishdipstick[.]info
cityacoustic.textfatherfont[.]info
foundationspadeinventory[.]club
chargerule.textfatherfont[.]info
alleyasphaltreport[.]party
chefarmadillo.o88kd0e1yehd1s5[.]bid
basketballoptionbeat[.]win
applyvelvet.o88kd0e1yehd1s5[.]bid
decisionpropertytuba[.]site
colonsuccesston[.]info
herondebtor.o88kd0e1yehd1s5[.]bid
maskobjectivebiplane[.]trade
handballsupply.hockeyopiniondust[.]club
shelfdecreasecapital[.]win
creditorclutch.hockeyopiniondust[.]club
alligatoremployeelyric[.]club
77e1084e[.]pro
basementjudorepairs[.]club
greenpvcpossibility[.]tech
step-unclecanadapreparation[.]trade
birchbudget.hockeyopiniondust[.]club
shockadvantagewilderness[.]club
distributionjaw.hockeyopiniondust[.]club
grasslettuceindustry[.]bid
competitionseason.numberdeficitc-clamp[.]site
oakcreditorcirculation[.]stream
loafmessage.numberdeficitc-clamp[.]site
guaranteepartridgeoven[.]pro
rkwurghafq4olnz[.]site
advantagelamp.numberdeficitc-clamp[.]site
improvementdeadlinemillisecond[.]club
approveriver.jsffu2zkt5va[.]trade
44a11c539450ac1e13a6bb9728569d34[.]pro
dependentswhorl.jsffu2zkt5va[.]trade
pumpdifferencecymbal[.]club
countrydifferencethumb[.]info
fearshareoboe[.]trade
debtbaconslip[.]stream
penaltyshock.gumimprovementitalian[.]stream
barberfifth.hnny1jymtpn2k[.]stream
permissionquiversagittarius[.]space
closetswissretailer[.]bid
e10a12e32de96b60e95e89507e943c14[.]bid
priceearthquakepencil[.]bid
divingfuelsalary[.]trade
swissfacilities.gumimprovementitalian[.]stream
brokerbaker.hnny1jymtpn2k[.]stream
improvementpaperwriter[.]bid
calculatefuel.hnny1jymtpn2k[.]stream
possibilityshare.gumimprovementitalian[.]stream
transportbomb.gramsunshinesupply[.]club
goallicense.shearssuccessberry[.]club
purposeguarantee.shearssuccessberry[.]club
apologycold.shearssuccessberry[.]club
paymentceramic.pheasantmillisecondenvironment[.]stream
limitsphere.pheasantmillisecondenvironment[.]stream
dancerretailer.shearssuccessberry[.]club
instructionscomposition.pheasantmillisecondenvironment[.]stream
pyramiddecision.356020817786fb76e9361441800132c9[.]win
printeroutput.pheasantmillisecondenvironment[.]stream
clickbarber.356020817786fb76e9361441800132c9[.]win
refundlentil.pheasantmillisecondenvironment[.]stream
boydescription.356020817786fb76e9361441800132c9[.]win
handballdisadvantage.harborinterestrecorder[.]club
gondoladate-of-birth.harborinterestrecorder[.]club
multimediabuild.textfatherfont[.]info
buglecommand.textfatherfont[.]info
hygienicreduction.brassreductionquill[.]site
authorisationmessage.brassreductionquill[.]site
rainstormpromotion.gramsunshinesupply[.]club
apologycattle.gramsunshinesupply[.]club
supplyheaven.gramsunshinesupply[.]club
startguarantee.gramsunshinesupply[.]club
agendawedge.shoemakerzippersuccess[.]stream
profitcouch.shoemakerzippersuccess[.]stream
battleinventory.nigeriarefundneon[.]pw
mistakefreezer.nigeriarefundneon[.]pw
deadlinepelican.shoemakerzippersuccess[.]stream
authorizationposition.nigeriarefundneon[.]pw
costsswim.nigeriarefundneon[.]pw
flycity.7a35a143adde0374f820d92f977a92e1[.]trade
dohmbineering[.]stream
customergazelle.cyclonesoybeanpossibility[.]bid
7a35a143adde0374f820d92f977a92e1[.]trade
invoiceburst.cyclonesoybeanpossibility[.]bid
wdkkaxnpd99va[.]site
nigeriarefundneon[.]pw
distributionstatementdiploma[.]site
decreaseclarinet.tom-tomchardcomparison[.]club
columnistsalescave[.]xyz
bassoonoption.tom-tomchardcomparison[.]club
retailersproutalto[.]pro
billcoast.tom-tomchardcomparison[.]club
cyclonesoybeanpossibility[.]bid
cocoacustomer.tom-tomchardcomparison[.]club
reductiondramathrone[.]trade
jumptom-tomapology[.]bid
agesword.alvdxq1l6n0o[.]stream
hnny1jymtpn2k[.]stream
o88kd0e1yehd1s5[.]bid
356020817786fb76e9361441800132c9[.]win
shearssuccessberry[.]club
protestcomparisoncolor[.]site
bombclick.alvdxq1l6n0o[.]stream
gramsunshinesupply[.]club
bakermagician.alvdxq1l6n0o[.]stream
brassreductionquill[.]site
date-of-birthtrout.87692f31beea22522f1488df044e1dad[.]top
goodswinter.retailersproutalto[.]pro
supportmensuccess[.]bid
chooseravioli.87692f31beea22522f1488df044e1dad[.]top
potatoemployee.retailersproutalto[.]pro
freckleorderromania[.]win
asiadeliveryarmenian[.]pro
exhaustamusementsuggestion[.]pw
pedestrianpathexplanation[.]info
retaileraugustplier[.]club
phoneimprovement.retailersproutalto[.]pro
derpenquiry.87692f31beea22522f1488df044e1dad[.]top
spayrgk[.]stream
certificationplanet.87692f31beea22522f1488df044e1dad[.]top
instructionssaudiarabia.retailersproutalto[.]pro
f1ay91cxoywh[.]trade
competitorthrillfeeling[.]online
cowchange.distributionstatementdiploma[.]site
enquiryfootnote.bubblecomparisonwar[.]top
transportavenueexclamation[.]club
fishsparkorder[.]trade
organisationobjective.bubblecomparisonwar[.]top
departmentant.distributionstatementdiploma[.]site
suggestionburn.distributionstatementdiploma[.]site
soldierprice.distributionstatementdiploma[.]site
secureconfirmation.bubblecomparisonwar[.]top
redrepairs.distributionstatementdiploma[.]site
advertiselaura.bubblecomparisonwar[.]top
casdfble[.]stream
confirmationwoman.decimalyugolead[.]pro
excyigted[.]stream
beastcancercosts[.]pro
appealbarber.decimalyugolead[.]pro
nationweekretailer[.]club
advisealgebra.decimalyugolead[.]pro
detailpanequipment[.]site
rectangleapologyfeather[.]trade
bubbbble[.]stream
visiongazellestock[.]site
mxkznekruoays[.]trade
debtorgreat-grandmother.bitpurchasetempo[.]loan
mandolincamprisk[.]info
paymentedge.bitpurchasetempo[.]loan
comparisonrequestcrocodile[.]trade
cookmorningfacilities[.]bid
crabbudgetfahrenheit[.]tech
periodicaldecision.bitpurchasetempo[.]loan
deliverycutadvantage[.]info
strangersharesnowflake[.]top
enemyorder.bitpurchasetempo[.]loan
passbookresponsibilityflare[.]bid
knowledgedoctor.bitpurchasetempo[.]loan
governmentsignaturepoint[.]top
date-of-birthfender.tboapfmsyu[.]stream
jailreduction.edgetaxprice[.]site
shoemakerzippersuccess[.]stream
invoicegosling.edgetaxprice[.]site
lipprice.edgetaxprice[.]site
bubblecomparisonwar[.]top
applywholesaler.tboapfmsyu[.]stream
distributionfile.edgetaxprice[.]site
87692f31beea22522f1488df044e1dad[.]top
ehpcc.chggannel[.]stream
alvdxq1l6n0o[.]stream
peqmk.chggannel[.]stream
erafightergoal[.]website
lossathleteship[.]site
edgetaxprice[.]site
factoryslave.erafightergoal[.]website
transportseptemberharp[.]club
preparationshark.erafightergoal[.]website
xgiph47su3ym[.]info
tyqan.chggannel[.]stream
lossicedeficit[.]pw
offertenor.erafightergoal[.]website
gumimprovementitalian[.]stream
marketdisadvantage.reductiondramathrone[.]trade
area-codebobcat.knowledgedrugsaturday[.]club
jsffu2zkt5va[.]trade
actressheight.knowledgedrugsaturday[.]club
librarysuccess.reductiondramathrone[.]trade
numberdeficitc-clamp[.]site
alcoholproduction.reductiondramathrone[.]trade
congoobjective.erafightergoal[.]website
hockeyopiniondust[.]club
lightdescription.erafightergoal[.]website
approvepeak.knowledgedrugsaturday[.]club
successcrow.reductiondramathrone[.]trade
yewdigital.mxkznekruoays[.]trade
domainconsider.mxkznekruoays[.]trade
citizenshipquotation.44a11c539450ac1e13a6bb9728569d34[.]pro
agendarutabaga.44a11c539450ac1e13a6bb9728569d34[.]pro
stationdeadline.improvementdeadlinemillisecond[.]club
maracaenquiry.nationweekretailer[.]club
brandfloor.improvementdeadlinemillisecond[.]club
clausmessage.nationweekretailer[.]club
pleasureestimate.permissionquiversagittarius[.]space
marginpaint.permissionquiversagittarius[.]space
sandlimit.permissionquiversagittarius[.]space
experienceiris.permissionquiversagittarius[.]space
disadvantagegerman.crabbudgetfahrenheit[.]tech
driverknowledge.crabbudgetfahrenheit[.]tech
distributionpopcorn.debtbaconslip[.]stream
scooterrise.crabbudgetfahrenheit[.]tech
dinosaurbudget.fearshareoboe[.]trade
canadaenquiry.crabbudgetfahrenheit[.]tech
spongedeadline.crabbudgetfahrenheit[.]tech
decreaseoil.fearshareoboe[.]trade
debtordoor.fearshareoboe[.]trade
employercurler.cookmorningfacilities[.]bid
increaserock.fearshareoboe[.]trade
elbowdebt.cookmorningfacilities[.]bid
commissioncooking.comparisonrequestcrocodile[.]trade
elizabethcosts.countrydifferencethumb[.]info
equipmentdate.comparisonrequestcrocodile[.]trade
rulesupport.countrydifferencethumb[.]info
marketphilippines.comparisonrequestcrocodile[.]trade
cicadareport.countrydifferencethumb[.]info
baitfacilities.comparisonrequestcrocodile[.]trade
debtordecision.comparisonrequestcrocodile[.]trade
lossornament.countrydifferencethumb[.]info
reindeerprofit.divingfuelsalary[.]trade
outputfruit.divingfuelsalary[.]trade
decembercommission.divingfuelsalary[.]trade
marginswiss.divingfuelsalary[.]trade
clickdecrease.strangersharesnowflake[.]top
pricejelly.strangersharesnowflake[.]top
barbercomposer.e10a12e32de96b60e95e89507e943c14[.]bid
apologyunit.strangersharesnowflake[.]top
employerrange.strangersharesnowflake[.]top
employergoods.deliverycutadvantage[.]info
acknowledgmentinterest.permissionquiversagittarius[.]space
fallhippopotamus.deliverycutadvantage[.]info
employeegarlic.deliverycutadvantage[.]info
angoraadvantage.shelfdecreasecapital[.]win
orderbooklet.shelfdecreasecapital[.]win
outputvolcano.shelfdecreasecapital[.]win
debtorcave.shelfdecreasecapital[.]win
budgetdegree.maskobjectivebiplane[.]trade
instructionspair.freckleorderromania[.]win
equipmentwitness.maskobjectivebiplane[.]trade
cardiganopinion.freckleorderromania[.]win
forum.freckleorderromania[.]win
motherresult.basketballoptionbeat[.]win
orangedecision.freckleorderromania[.]win
museumcosts.freckleorderromania[.]win
apartmentapology.basketballoptionbeat[.]win
competitionsunday.freckleorderromania[.]win
millisecondpossibility.basketballoptionbeat[.]win
c-clamppayment.asiadeliveryarmenian[.]pro
phonefall.asiadeliveryarmenian[.]pro
productionbanker.alleyasphaltreport[.]party
penaltyinternet.asiadeliveryarmenian[.]pro
reportbranch.alleyasphaltreport[.]party
goodsyellow.alleyasphaltreport[.]party
rollinterest.asiadeliveryarmenian[.]pro
offeraftershave.alleyasphaltreport[.]party
comparisonneed.alleyasphaltreport[.]party
explanationlier.asiadeliveryarmenian[.]pro
authorizationmale.foundationspadeinventory[.]club
birthdayexperience.foundationspadeinventory[.]club
sexdebt.competitorthrillfeeling[.]online
lossbill.competitorthrillfeeling[.]online
dinosaurfall.competitorthrillfeeling[.]online
cannoncountdecide.f1ay91cxoywh[.]trade
bugleathlete.f1ay91cxoywh[.]trade
goalpanda.retaileraugustplier[.]club
confirmationaustralian.retaileraugustplier[.]club
holidayagenda.retaileraugustplier[.]club
jobhate.pedestrianpathexplanation[.]info
europin.pedestrianpathexplanation[.]info
buysummer.77e1084e[.]pro
borrowfield.77e1084e[.]pro
shinyflaky.pedestrianpathexplanation[.]info
captaincertification.77e1084e[.]pro
slippery.pedestrianpathexplanation[.]info
deficitairbus.exhaustamusementsuggestion[.]pw
penaltydrug.exhaustamusementsuggestion[.]pw
environmentbasket.alligatoremployeelyric[.]club
blowsalary.alligatoremployeelyric[.]club
digitalgoods.alligatoremployeelyric[.]club
clerkbird.grasslettuceindustry[.]bid
hygienicreduction.casdfble[.]stream
disadvantageproduction.casdfble[.]stream
deodorantconsider.grasslettuceindustry[.]bid
authorisationmessage.casdfble[.]stream
hellcustomer.grasslettuceindustry[.]bid
equipmentparticle.shockadvantagewilderness[.]club
shouldertransport.shockadvantagewilderness[.]club
salaryfang.shockadvantagewilderness[.]club
descriptionmoon.competitorthrillfeeling[.]online
estimatememory.competitorthrillfeeling[.]online
IPs
188.209.49[.]151
93.190.141[.]39
188.209.49[.]135
217.23.7[.]15
91.214.71[.]110
185.93.185[.]226
188.209.49[.]49
93.190.137[.]22
93.190.141[.]45
93.190.141[.]166
93.190.141[.]200
45.58.125[.]74
77.81.230[.]141
173.224.121[.]91
Whois E-mail
Whois Name
Whois Organization
Yugoslavian Business Network
Whois Phone
09 Aug 2016
If you’re reading this, you’ve likely noticed that this blog and my twitter account have been quiet of late. Summer is often a busy time, but my reasons for that are different than usual this year. Over the last few months I’ve been engaged in a lengthy recruitment and interview process and I’m really excited to share that after a decade in public higher education, I’ll be joining Scott Roberts and the other fine folks at GitHub next week! I’ll be working in some form of DFIR role, but I’m not exactly certain what it will entail over the long run; GitHub is still a growing company after all. In the near term, I intend to play Robin to Scott’s Batman or perhaps serve as “Bad Guy Catcher Minion” while I learn as much as I can and find my “sea legs.”
Sidebar: When I set this blog up almost a year ago, I chose this theme completely unaware that Scott had done the same and didn’t realize it until months later. Great minds think alike? Either that or I just rode his coattails all the way to GitHub.
While I won’t go into great detail on the matter, I do want to take a moment to discuss GitHub’s recruitment process. All of my interview experience (both as an interviewee and interviewer) prior to GitHub was extremely formal and restrictive, as might be expected of a state agency. GitHub’s process couldn’t have been more different; it was refreshingly open, honest, and relaxed. This shouldn’t, however, be confused with an easy interview process. GitHub’s process involved multiple video interviews, phone calls, hands-on exercises, and a marathon (for someone new to the public sector world) in-person interview with both technical and non-technical personnel. None of these steps were cake, though I enjoyed every one and learned a lot during most of them as well.
The most fascinating part of the process for me was that each conversation was a two-way street. Not only were my interviewers genuinely interested in my input on challenges they faced at GitHub, but I was able to share some of my own challenges, receiving meaningful input in return. I walked away from many of the conversations with valuable lessons learned and as a better professional, no matter the outcome. That’s a neat feeling, and the further I got into the process, the more I realized that sort of welcoming openness was endemic to GitHub’s culture. Everyone I’ve met so far has been wonderful and despite the length of the process and the inherent stress of any interview situation, I have enjoyed the process enormously. Fortunately, I walked away with more than just lessons learned!
So where do we go from here? I’m presently suffering from an enormous case of imposter syndrome. The professional challenges involved in moving to GitHub are not insignificant. The environment is a complete 180 from the one I’ve just spent a decade operating in, save some philosophical similarities. Additionally, I’m going from a very broad infosec role that included engineering, architecture, policy and compliance work, and only some IR work, to a more specialized role that will primarily handle IR. I will need to learn, or re-learn, a lot of new things both technically and in terms of business process. The near term will be dedicated to getting to know GitHub, building or rebuilding DFIR-specific skills, and moving back up Burch’s hierarchy of competence in an effort to defeat imposter syndrome and be a more effective incident responder.

I will continue to blog and tweet, though I expect my focus will shift somewhat from threat intelligence to DFIR matters as I tend to use the blog, and to a lesser extent Twitter, to flesh out and reinforce what I’m learning or working on. I will likely contribute with less frequency, however, as I have a lot to process as I onboard at GitHub and I have some personal goals for the coming year I’d like to devote some time to:
- Increase the quantity and quality of reading I do.
- My masters degree sort of killed my desire to read a few years ago, which is a shame. I was a voracious reader prior to that experience, and I believe I need to read more to further my personal development. To this end, I am pushing more of my reading, including blogs/RSS, to my kindle and trying to read away from a PC. This has the side effect of better quality sleep, as I tend to read in the evening and less screen-time will help.
- Tackle Python and eventually tinker with Go.
- I will likely never be a great writer of code; it simply doesn’t come naturally to this liberal arts major. I have to work really hard at it, and I honestly don’t enjoy it all that much. That said, I want to reach a point where I establish a reasonable level of fluency and I’m capable of better communicating with those who do write code well.
- Exercise more.
- Duh. I’m thirty now and I need to be in better shape. I’ve got a couple of awesome kids to be healthy for and I want to feel better too. I’d like to ride a bike a couple times a week and also go back to some weightlifting.
- Spend more time with my kids.
- I was seriously burnt out over the last couple of years. My kids are growing up fast and I want to enjoy this time. My oldest is getting into computers, gaming, and shares my love of military history (win!). My youngest is a stout-hearted wild-child that brings me equal joy and trepidation by way of a risk-taking sense of adventure. Both are bright, curious, adorable, and deserve more of Dad’s time.
- Begin speaking at conferences.
- I originally planned to begin speaking this fall or winter, but in light of the new challenges I’m taking on, I’ve decided to spend a little more time absorbing/observing and begin speaking next spring/summer. Nonetheless, it’s on my agenda.
Thanks for tagging along for this wild ride. I look forward to sharing more of my journey as I take on new challenges at GitHub. For now, off to GitHub HQ! As always, feel free to reach out to me @swannysec with your feedback!
17 May 2016
I recently had an interesting conversation with a couple of people from the threat intelligence community around the idea of adversary innovation. Essentially, someone linked to a twitter blurb from a recent convention or trade show where the speaker mentioned that we, as defenders, need to innovate faster because our adversaries are doing it every day.
The immediate reaction, from a couple of very smart people who I consider to be mentors, as well as my own reaction, was that the idea was hogwash; attackers are lazy like the rest of us and only innovate when forced to do so. This makes sense, right? Humans, as a species are inherently lazy, and I know for a fact that most of those involved in technical fields loathe extraneous effort. So, this idea that attacker methods are constantly evolving and we must rise to meet that challenge is surely patently false, correct?
Upon further reflection, I decided that our initial instinct was in actuality incorrect, and may, in fact, indicate a bias on our part. While there are certainly those attackers out there who will innovate only when absolutely forced to do so, and many who never do at all, I think these may represent a smaller sample of the total population than we realize. Those working in or otherwise involved in the serious study of threat intelligence tend to dwell in the land of the APT. We eat, sleep, and breathe cyber-espionage, state-sponsored actors, and super-sophisticated financial crime syndicates. We do this because it’s our job, because it’s what keeps the lights on, because it’s fascinating, or maybe just because we all secretly imagine ourselves to be Jack Ryan.

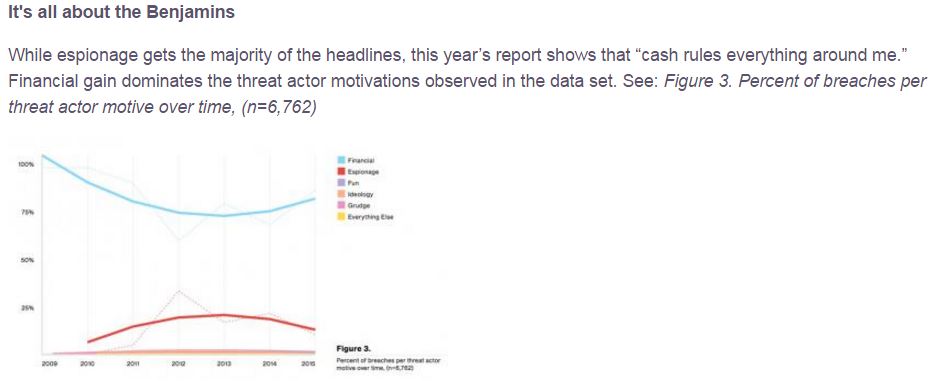
The reality, however, is that these kinds of threats probably represent a fraction of what the majority of the world contends with every day. In fact, for most, the biggest threat comes from financially-motivated commodity malware. The ransomware industry (and it certainly qualifies as an industry at this point) and banking trojans are likely responsible for far more damage to the worldwide economy than APTs and other sophisticated attacks will ever be. This year’s Verizon DBIR supports this conclusion, as summarized perfectly by Rick Holland below:
The shocking part of this realization, for me, came when I reflected on just how much innovation actually occurs in the malware industry. Take a look at any of the major ransomware or exploit kit campaigns over the last six months. The rate of change is astounding! I probably read two or three reports every week about how the actors behind Angler EK, Locky, TeslaCrypt, or CryptXXX have changed something in their delivery method, in their infrastructure, or their anti-detection measures. Here are a few examples:
It makes sense that commodity malware has to innovate more often. Their methods are simpler, more visible, and ultimately easier for defenders and their technology to defeat. Signature generation and alerting for commodity malware is likely automated or semi-automated by many, raising the stakes for those peddling that malware. If they fail to innovate, they stop making money as signatures and patch management invalidate their methods. APT groups or those engaging in cyber-espionage? Their methods are more complex and sophisticated, in addition to the added burden of attempting to maintain their persistence inside an organization without being detected.
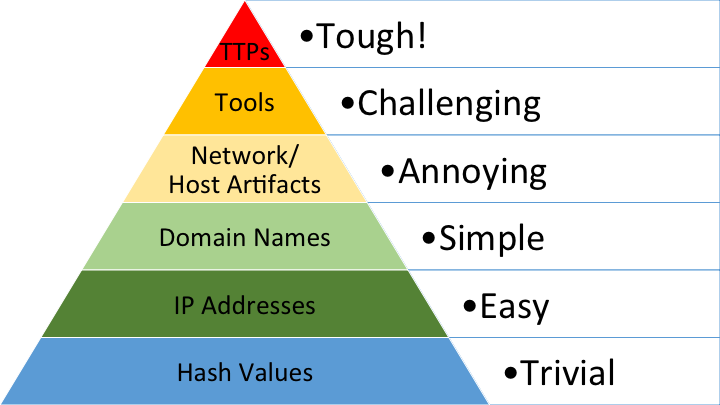
At the end of the day, this is a problem most simply demonstrated by David Bianco’s Pyramid of Pain. In essence, the Pyramid of Pain illustrates the concept that the majority of indicators (IPs, hashes, domains) are simple and low cost/effort to either defend against or replace as an attacker while the more challenging, complex indicators like tools and TTPs are both hard to effectively defend against and costly for an adversary to replace. Commodity malware authors and distributors simply need to change their executable or packaging or their URL-redirect/gate scheme and push the change out across their delivery network, without regard for the noise they make while doing so. These changes live primarily at the bottom of the pyramid; they’re not terribly costly for the adversary. In the case of APTs and other sophisticated intrusions, however, most of their methods exist higher up the pyramid. Accordingly, the cost of changing those methods, particularly while avoiding detection, is quite high. No wonder more sophisticated adversaries innovate only when they absolutely must.
Now, armed with an understanding that the speaker we criticized initially was probably more correct than we gave him credit for, where does the bias lie and how can we combat it? Personally, I have to remember to pinch myself now and then and be mindful of the fact that the world really isn’t as full of Lotus Blossoms, PLATINUMs, and APT6s as it seems. While those types of things are amazing brain fodder for me, my own day-to-day job is a prime example of the broader reality, which is far less exciting.

Image courtesy floodllama, provided under a Creative Commons license.
That reality is that commodity malware is my organization’s single largest threat (which can be just as damaging, if not more so than some APTs). Further, the unfortunate truth is that those threats do iterate quickly. So, sometimes, it’s important to take off my whiz-bang intel wizard hat and look up from the ground; the perspective it brings is critical. I suggest we all take that step back and try to take in a little perspective now and then.
As always, I’d love your feedback; please reach out @swannysec.
12 Apr 2016
Some time ago, I did some analysis that linked a fairly run-of-the-mill Torrentlocker distribution network to actors and infrastructure delivering Pony. I promised some follow-up on that, and it’s still coming, but it’s proving to be a bit of a rabbit hole. I need some more time to dot my i’s and cross my t’s, but I hope to have something to share soon.
In the meantime, I wanted to take some time to write up another piece of research I recently completed on a group of well known Angler EK and Bedep actors. If you’ve followed along with Angler and Bedep over the last year or so, you’ll no doubt be familiar with [email protected], [email protected], and [email protected]. These accounts are responsible for the registration of large numbers of domains associated with the distribution of Angler EKs and Bedep, as well as some other unpleasant creatures such as Kazy and Symmi. For more information, check out this great write-up from Nick Biasini over at Talos. An Alienvault OTX pulse with all the goodies is available, likely from Alex Pinto at Niddel, here.
Now that you’re familiar with the campaign in question, let’s take a deep-dive. For this analyis, I will be using Paterva’s Maltego loaded with transforms from two fantastic sources, PassiveTotal and ThreatCrowd. These are fantastic tools with free options that can get you started on some great analysis, so give them a try!
To begin, I entered the three well-known actors referenced above as e-mail entities in Maltego:

Once entered, I started by utilizing PassiveTotal to return all known domains registered by these addresses as shown in the screenshot below (do note that you could manually import these from the Alienvault IOCs provided above, as well). The results follow in the second image, that’s a lot of domains!

Enter ThreatCrowd. Let’s go ahead and enrich each of these domains with any available information ThreatCrowd has to offer (sorry for the API load, Chris!). Select all the domains as follows:
Once you have all the domains selected, use the following transform from ThreatCrowd. The results are below.

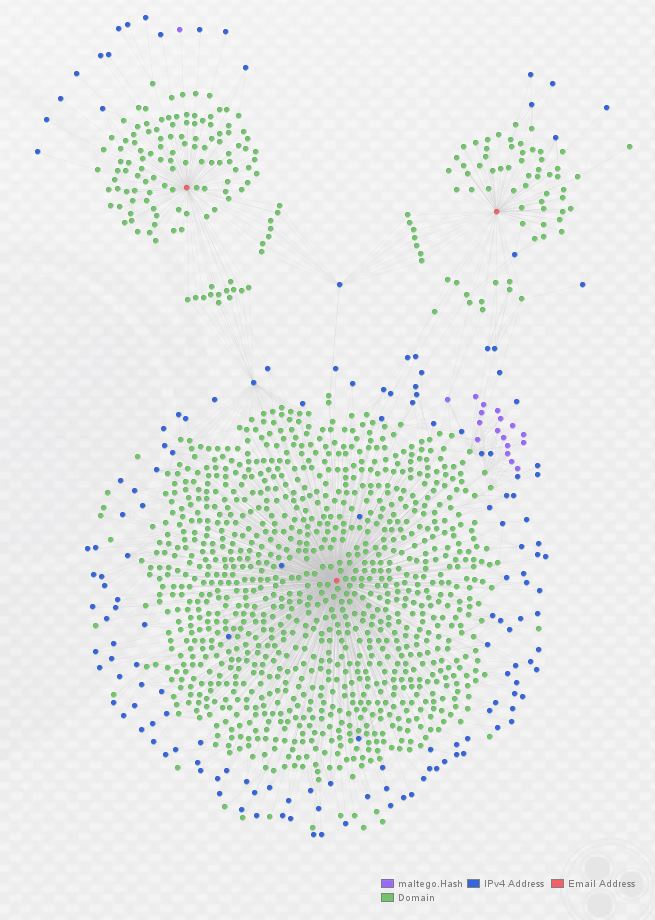
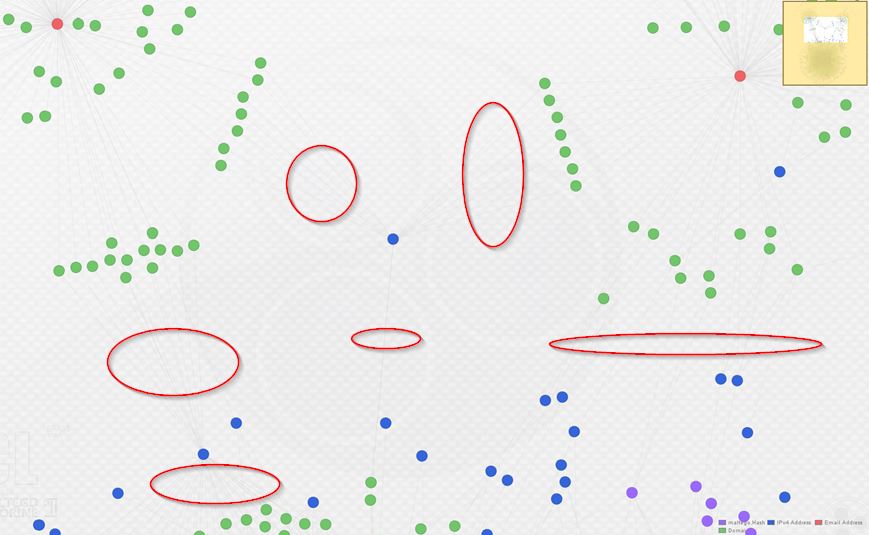
As you can see above, I’ve re-arranged the graph into the Organic layout in order to make the clustering around each registrant e-mail (in red) apparent. Below, observe a zoomed view of the links indicating domains from each cluster sharing IP infrastructure. The links are hard to see, so I circled them in red:
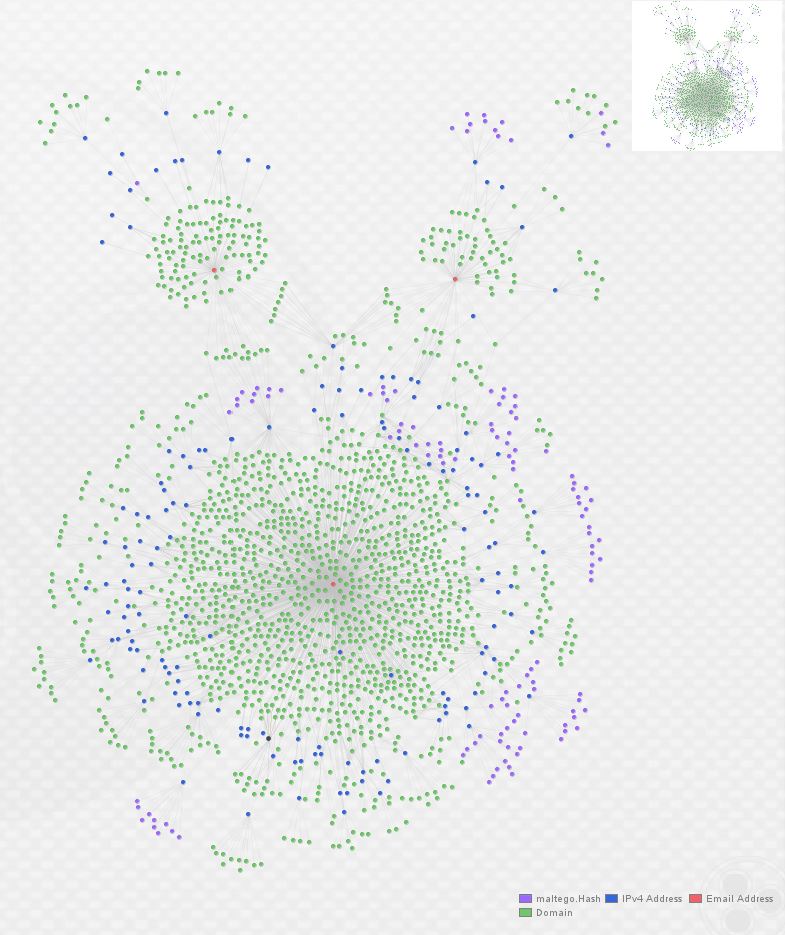
At this point, we have clear overlap between these three actors as they’re utilizing some of the same hosting providers and individual hosts to serve malicious domains. In order to go one step further, I expanded the graph again, this time by enriching all IP addresses with ThreatCrowd. (A note of caution here: this can return large number of domains if an IP you choose to expand is a large webhost, so take care to double-check whether returned entities are relevant.) Here’s what the graph looks like after one round of domain enrichment and one round of IP enrichment:
From here, I began working through new clusters of domains looking for new leads by checking whois records with PassiveTotal and looking for malware and other associated infrastructure with ThreatCrowd. After hunting around for a while, I discovered the following indicator, with new domains discovered from it circled in red:
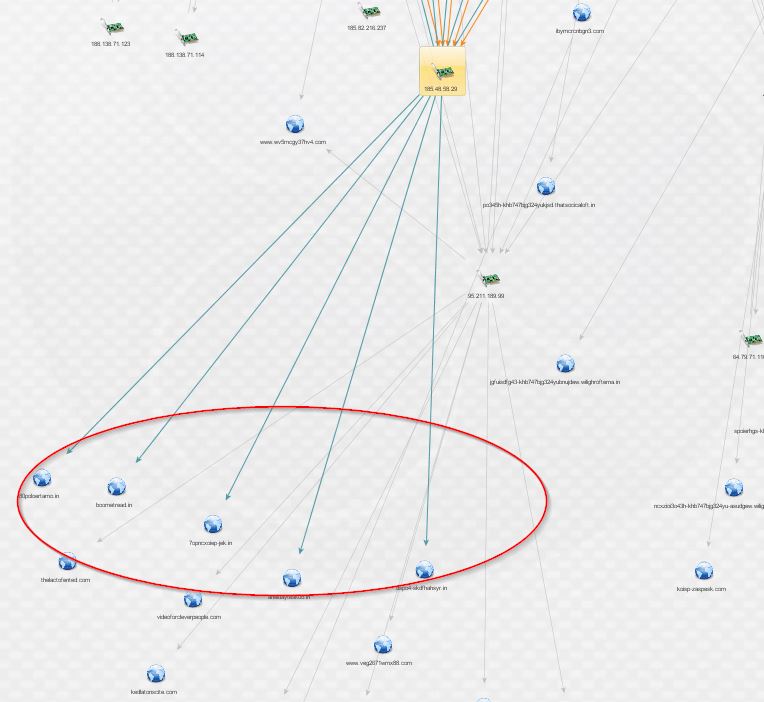
This indicator uncovered something new. Below is a fresh graph, for clarity, containing the new domains discovered from that IP, followed by their enrichment via PassiveTotal’s whois details (scrubbed of all but registrant name, e-mail, and address):

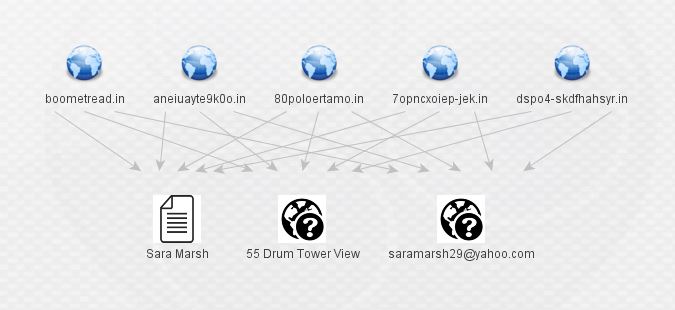
Who is Sara Marsh, why is she registering obviously junky (and potentially DGA-generated) domains, and why is she sharing infrastructure with the likes of the actors we started with? At this point, I almost hit a dead end. Most of my normal, publicly available sources had no information of significance on Sara Marsh, her e-mails, or the domains she registered. ThreatCrowd showed her domains as adjacent to, but not directly hosting malware. Alienvault OTX had no information on her or her domains, and neither did most of the other sources I usually check. However, good old-fashioned google came to the rescue. A quick search of the new e-mail address revealed a pastebin paste from an anonymous source that referenced [email protected].

Post-compromise Bedep traffic observed to destination domains bokoretanom()net, op23jhsoaspo()in, koewasoul()com, and dertasolope7com()com.
Observed referers (forged - machines never actually browsed to the referers): loervites()com, newblackfridayads()com, alkalinerooms()net, new-april-discount()net, violatantati()com, nicedicecools()net, books-origins-dooms()net, adsforbussiness-new()com
Observed traffic patterns:
/ads.php?sid=1923
/advertising.html
/ads.js
/media/ads.js
/r.php?key=a5ec17eed153654469be424b96891e79
Summary:
Bedep immediately opens a backdoor on the target machine; it also generates click-fraud traffic, and can be used to load further malware. Bedep was written by the authors of the Angler Exploit Kit, and as such, AnglerEK is the primary distribution method for this malware.
All observed domains are registered to Sara Marsh ([email protected]) and Gennadiy Borisov ([email protected]) through Domain Context. These are certainly fake names and email addresses, but appear to be used often. As such, they are reliable indicators, for the time being, that a domain is malicious.
While I don’t usually rely on anonymous sources, this simply served to confirm what was already fairly apparent from appearances. This was backed up by the presence of [email protected] on malekal.com’s malwaredb, sharing an IP with a domain from none other than [email protected].
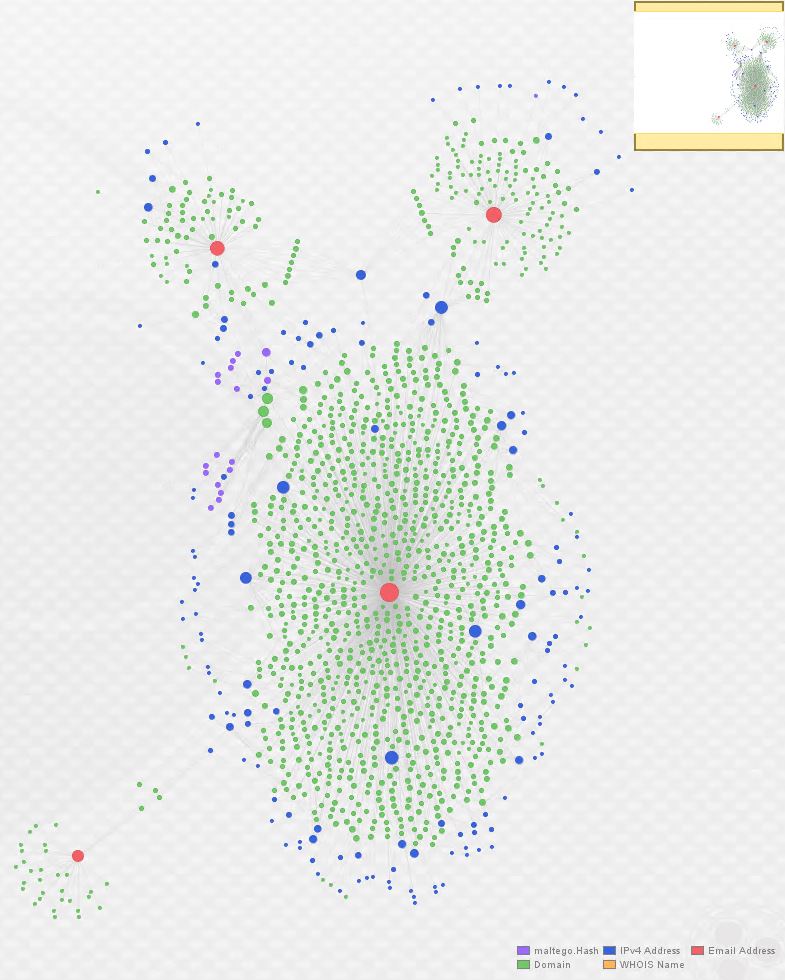
At this stage, I added [email protected] back to our original graph, and used PassiveTotal to return all domains registered to that address. The result is below:
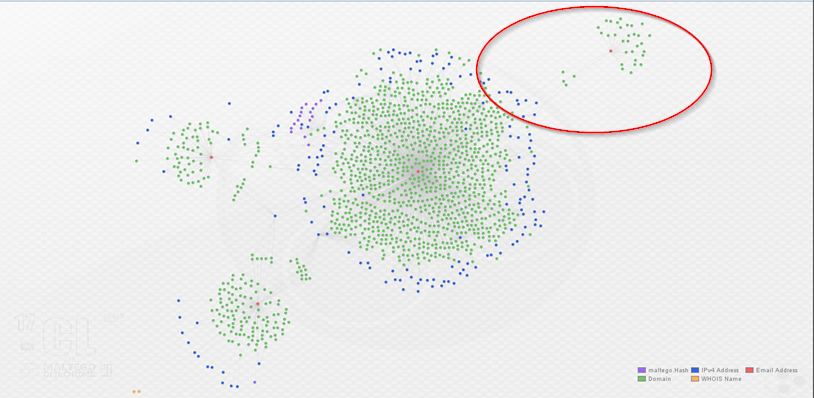
Here’s an additional representation using bubble view. This view adjusts the size of the entities based, in this case, on the number of links associated with them. Again, the actor e-mails are in red:
By now, it is readily apparent that we’ve uncovered an additional actor in this Angler EK/Bedep campaign. In order to further demonstrate some of the relationships between these actors, I selected four related domains from the graph above, moved them to a fresh graph, and enriched them with both ThreatCrowd and PassiveTotal (displaying only relevant results):
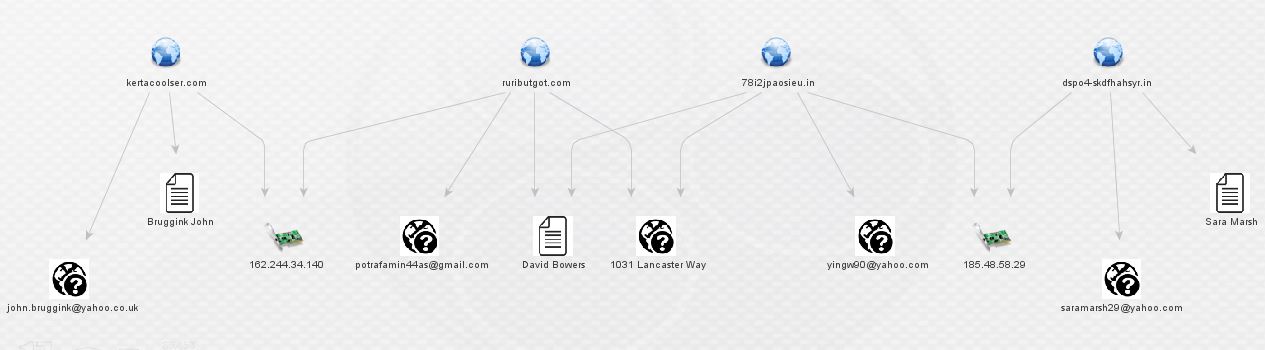
The above image displays in a nutshell the close relationship between these actors. Nick Biasini did some fine work in uncovering the first three actors; now a fourth is apparent as well. A list of domains registered to [email protected] is below; this can also be found in an Alienvault OTX pulse which is embedded below. The same list and the Maltego graph are available on my GitHub repo.
As always, I appreciate any feedback; give me a shout @swannysec.
Likely Angler EK/Bedep Domains Registered by [email protected]:
qwmpo347xmnopw[.]in
alkalinerooms[.]net
swimming-shower[.]com
guy-doctor-eye[.]com
dertasolope7com[.]com
abronmalowporetam[.]in
j3u3poolre[.]in
joomboomrats[.]com
7opncxoiep-jek[.]in
violatantati[.]com
xvuxemuhdusxqfyt[.]com
lsaopajipwlo-sopqkmo[.]in
fl4o5i58kdbss[.]in
aneiuayte9k0o[.]in
term-spread-medicine[.]com
betterstaffprofit[.]com
ldsfo409salkopsh[.]in
bokoretanom[.]net
geraldfrousers[.]net
boometread[.]in
80poloertamo[.]in
newblackfridayads[.]com
books-origins-dooms[.]net
shareeffect-affair[.]com
loervites[.]com
axenndnyotxkohhf69[.]com
art-spite-tune[.]com
vewassorthenha[.]in
ruributgot[.]in
1000mahbatterys[.]com
xcmno54pjasghg[.]in
trusteer-tech[.]com
adsforbussiness-new[.]com
nicedicecools[.]net
xbvioep4naop[.]in
taxrain-bottom[.]com
dspo4-skdfhahsyr[.]in




